Analyzing representational similarity among neural networks (NNs) is essential
for interpreting or transferring deep models. In application scenarios where numerous
NN models are learned, it becomes crucial to assess model similarities
in computationally efficient ways.
In this paper, we propose a new paradigm for
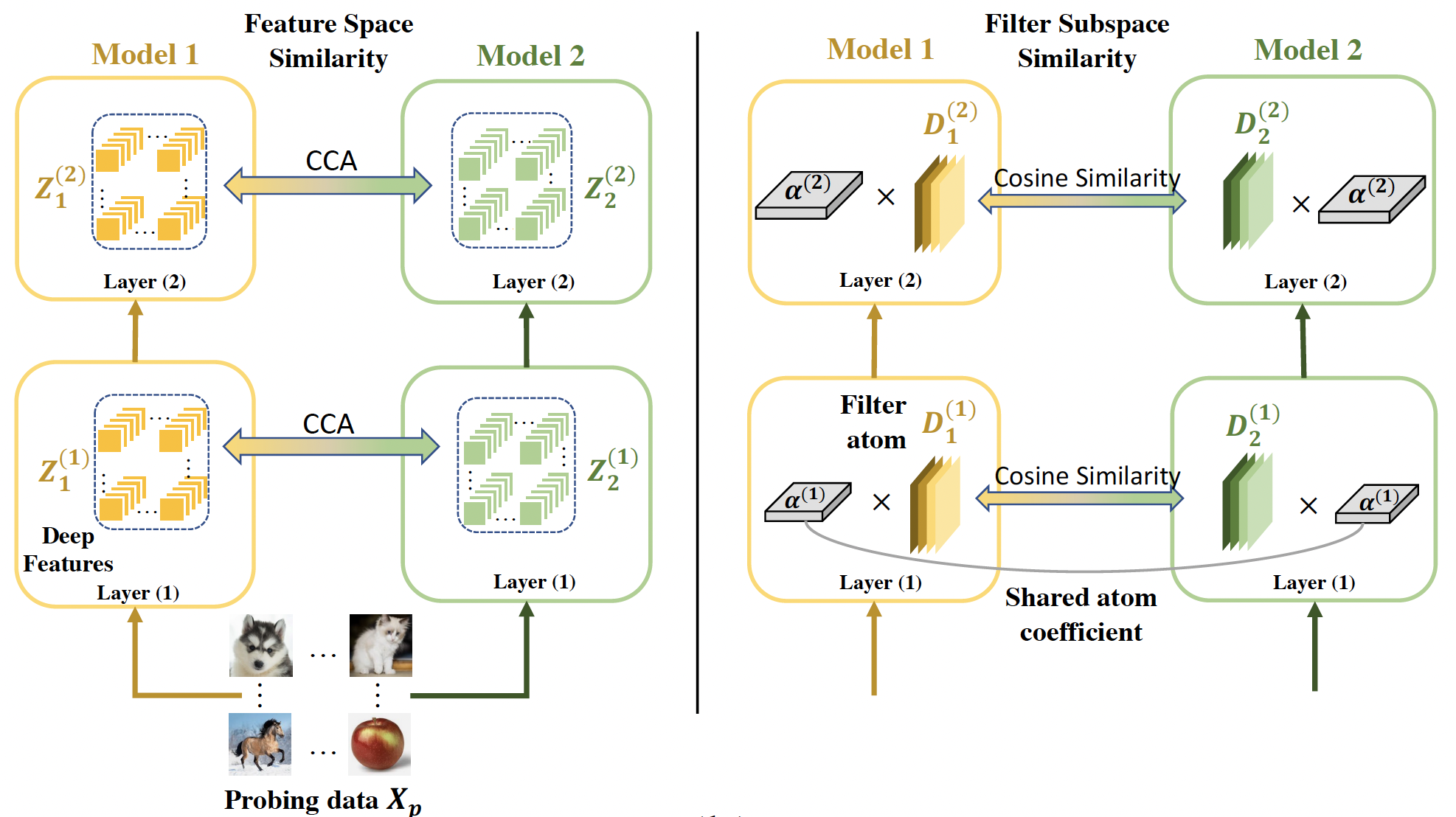
reducing NN representational similarity to filter subspace distance. Specifically,
when convolutional filters are decomposed as a linear combination of a set of
filter subspace elements, denoted as filter atoms, and have those decomposed atom
coefficients shared across networks, NN representational similarity can be significantly
simplified as calculating the cosine distance among respective filter atoms,
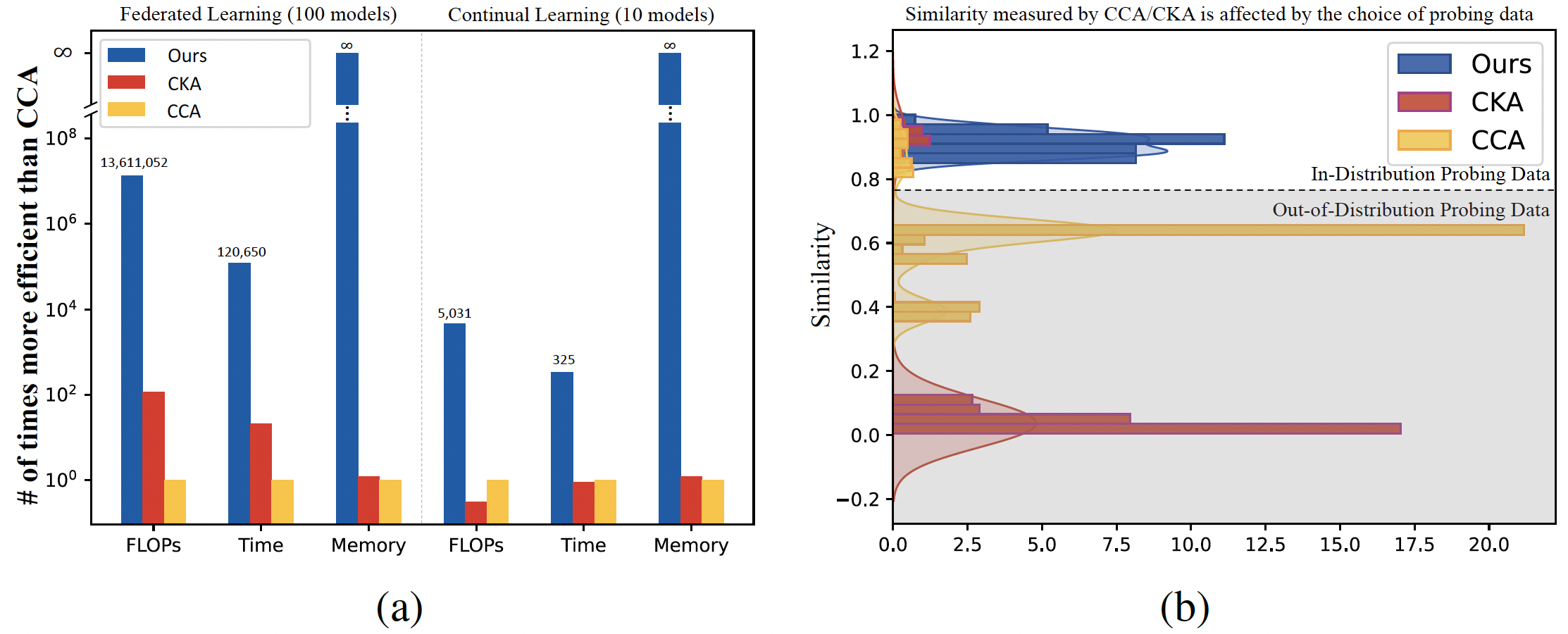
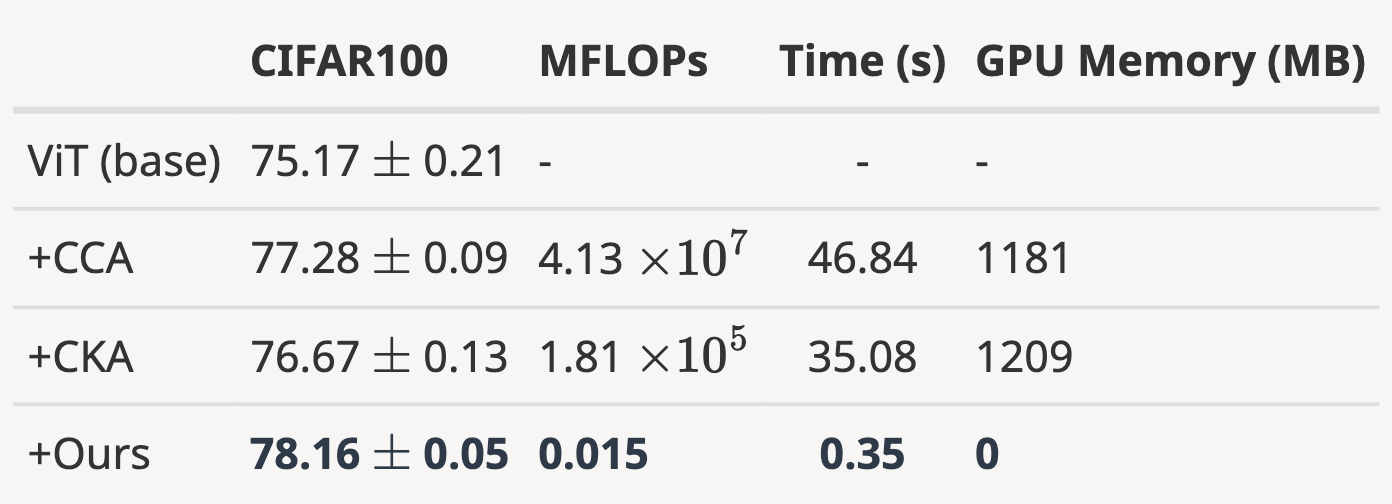
to achieve millions of times computation reduction over popular probing-based
methods.
We provide both theoretical and empirical evidence that such simplified
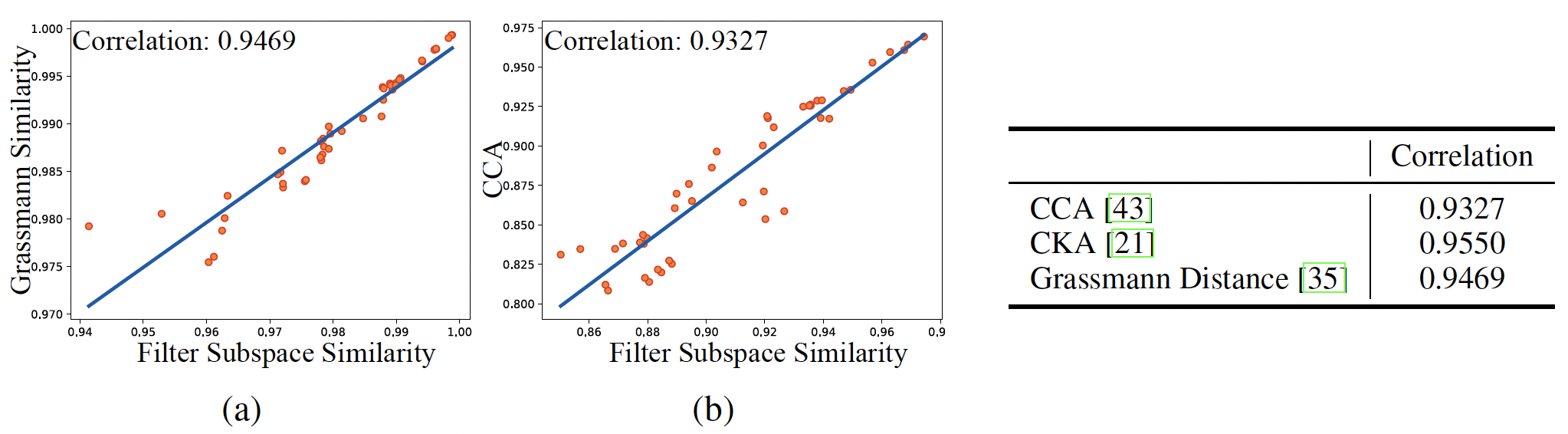
filter subspace-based similarity preserves a strong linear correlation with other
popular probing-based metrics, while being significantly more efficient to obtain
and robust to probing data. We further validate the effectiveness of the proposed
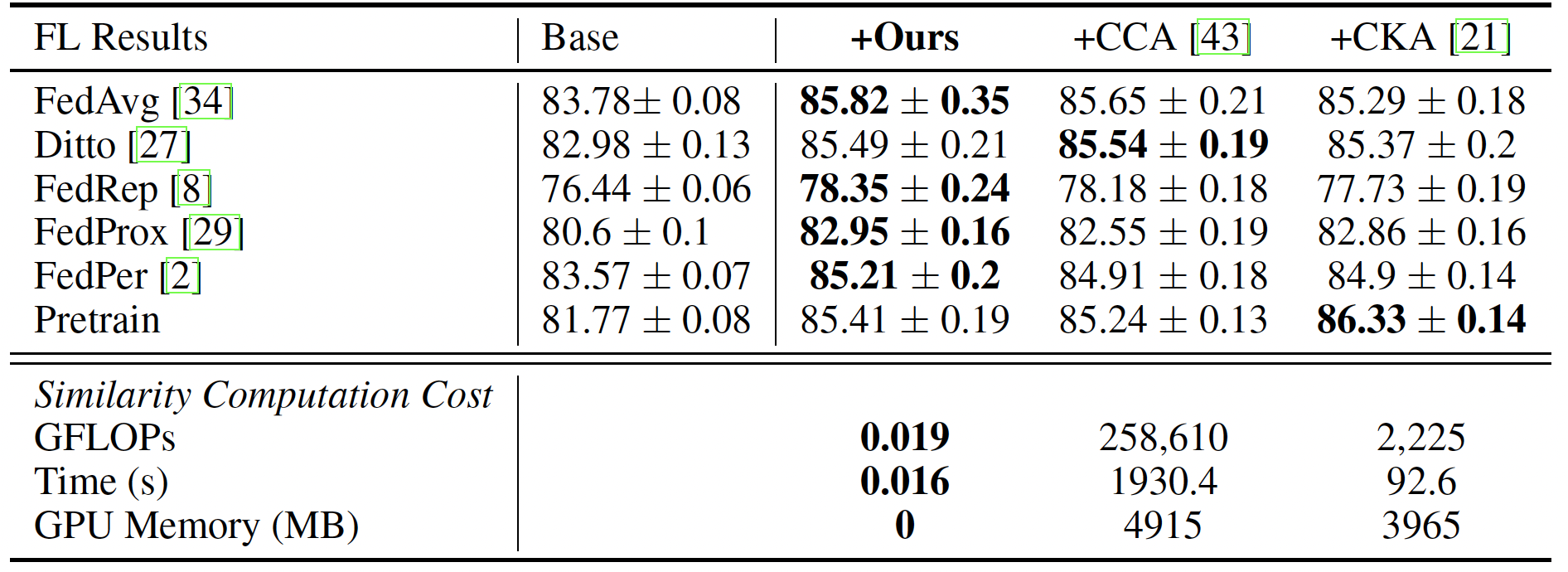
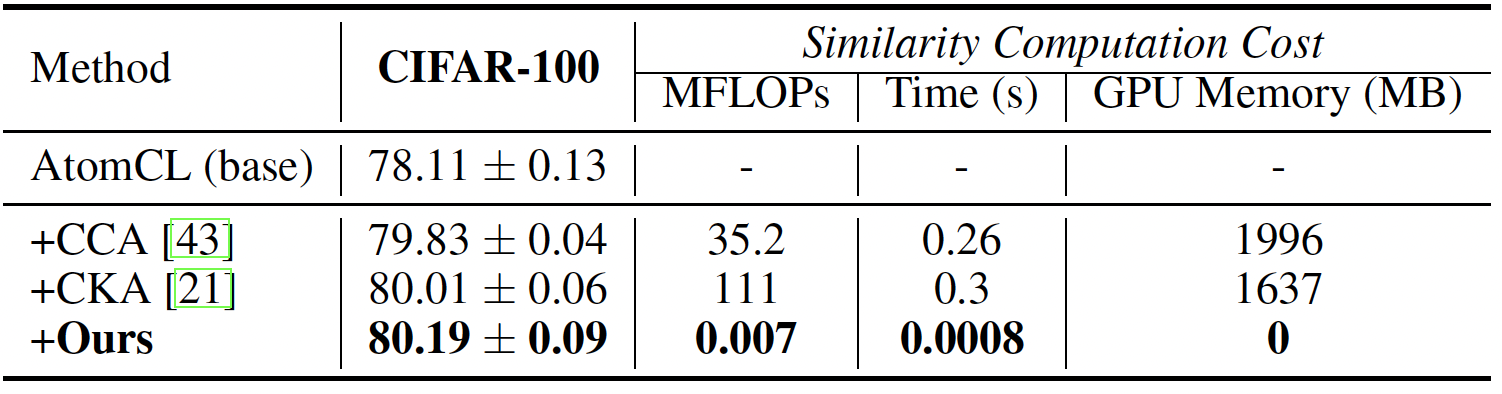
method in various application scenarios where numerous models exist, such as
federated and continual learning as well as analyzing training dynamics. We hope
our findings can help further explorations of real-time large-scale representational
similarity analysis in neural networks.